简单NLP — 情感分析
前几天面试的时候,面试官突然问我“为什么想选择数据科学相关的专业?” 一时语塞,说我纯粹的热爱吧好像又有些虚伪,无非就是为了混口饭吃,哪有什么宏大叙事和美好愿景。
但是,我这样回答面试官的:我说也许在我们不知道的情况下,一些简单的数据分析能给我们带来很多信息,这些信息可以是商业上的,也可以是社会上的,甚至可以是个人的。因为我有每天记日记的习惯(虽然大部分是在写废话。。。),然后前几天刚好用Hugging Face上开源的模型简单跑了一遍对每天日记的情感分析。我回答面试官,大概,数据分析也能让我更好的认识自己吧。
所以开一个“简单”系列,就是无脑调包就好了,没什么技术含量。
0, 我的日记
这是我记日记的习惯,写一些话,然后没有标点符号(亏贼这太变态了),靠换行来断句。在python里,数据大概长这样: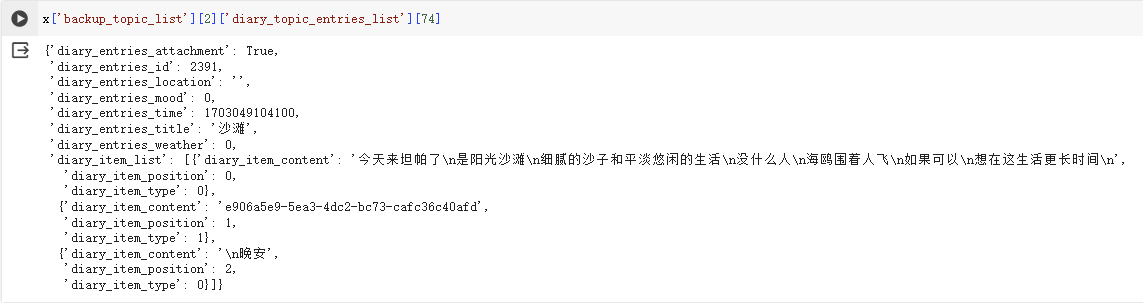
我要的其实就是diary_item_content里的内容,一顿操作后提取内容,在简单做点预处理准备分析。(此处无码,因为每个人写日记的习惯都不一样罢。)

1, 直接调用在线模型
1.1 Hugging Face
在Hugging Face,有众多深度模型可供选择。可以用来微调也可以直接拿来使用。(拿来吧你!)
我点兵点将选择了xuyuan-trial-sentiment-bert-chinese,一个在bert上微调用中文数据集微调的情感分析模型。输入文本,输出大致如下:
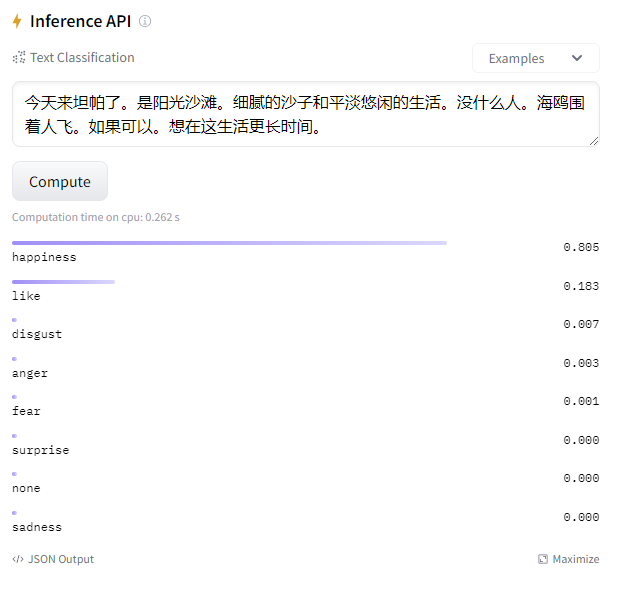
乍一看,看挺准的吼。
1.2 Python 调用
在python里的调用很简单,直接
from transformers import pipeline #直接使用高级API
pipe = pipeline("text-classification", model="touch20032003/xuyuan-trial-sentiment-bert-chinese") #可自选模型使用例:
pipe('今天来坦帕了。是阳光沙滩。细腻的沙子和平淡悠闲的生活。没什么人。海鸥围着人飞。如果可以。想在这生活更长时间。')
# output: [{'label': 'happiness', 'score': 0.8051121234893799}]
#or
pipe('今天来坦帕了。是阳光沙滩。细腻的沙子和平淡悠闲的生活。没什么人。海鸥围着人飞。如果可以。想在这生活更长时间。', top_k=None) #top_k = None 返回所有分类
#[{'label': 'happiness', 'score': 0.8051121234893799},
# {'label': 'like', 'score': 0.18319253623485565},
# {'label': 'disgust', 'score': 0.006669812370091677},
# {'label': 'anger', 'score': 0.0025043778587132692},
# {'label': 'fear', 'score': 0.0013982513919472694},
# {'label': 'surprise', 'score': 0.0004570793535094708},
# {'label': 'none', 'score': 0.0004206936282571405},
# {'label': 'sadness', 'score': 0.0002451551263220608}]1.3 简简单单,写个for循环
代码就不放了,还是那句话,具体情况具体分析。也写得过于丑陋,不好意思放。
我把结果存为了一个字典,key是第几篇日记,value是不同段落的情感。
print(res)
#{0: {0: 'like', 1: 'anger'},
# 1: {0: 'happiness', 1: 'like', 2: 'sadness', 3: 'disgust', 4: 'happiness'},
# 2: {0: 'sadness', 1: 'sadness'},
# 3: {0: 'disgust', 1: 'none', 2: 'sadness'},
# 4: {0: 'disgust', 1: 'happiness'},
# 5: {0: 'sadness'},
# 6: {1: 'disgust'},
# .....可以写个pickle存到本地:
import pickle
with open('DiarySentimentRes', 'wb') as f:
pickle.dump(res, f)2, 我的情绪
接着,简单粗暴的统计了一下每个情感的个数。
sentiCount = {'sadness':0, 'happiness':0, 'like':0, 'anger':0, 'surprise':0, 'disgust':0, 'fear':0, 'none':0}
for i,j in res.items():
for m,n in j.items():
if type(n) == list:
for k in n:
sentiCount[k]+=1
else:
sentiCount[n]+=1
print(sentiCount)
'''
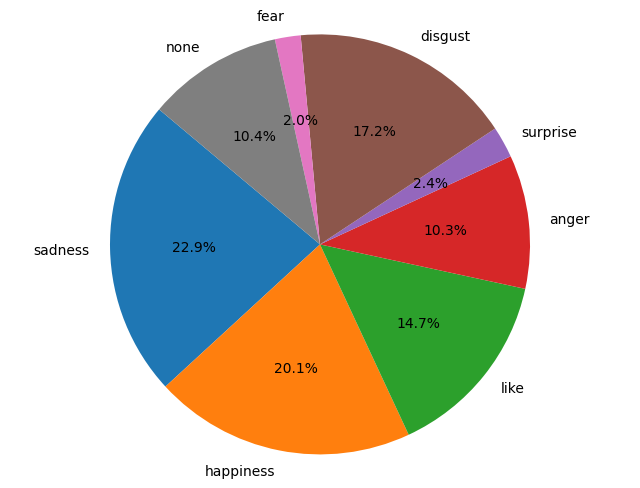
{'sadness': 1227,
'happiness': 1075,
'like': 784,
'anger': 550,
'surprise': 129,
'disgust': 918,
'fear': 106,
'none': 558}
'''(开心和伤心居然五五开了,可能是每天大半夜才记日记,深夜emo吧😟)
简简单单画个饼状图,
3, 简单总结一下
在AI火热的今天,操作也逐渐便的简单化,直接使用模型,不需要过多的解释,大部分人都可以接触并快速上手对AI感兴趣的部分。AI绘图甚至都有开源的图形界面,连打python这种胶水语言都免了。所以一切都是那么简单(如果不深究的话,也许)。
谈回情感分析,其实也可以自己训练一个分类器(SVM, Logistic Regression……),效果也不见得比所谓的深度学习模型差。说白了,如果有合适的数据集,硬train一发或许更好。
4, 一些小概念
没错我喜欢把概念的东西放到后,不然一上来就是各种之乎者也,看得头疼。
- Transformer(变形金刚(不是)):一种编码器—解码器(encoder—decoder)架构。在Attention is All You Need提及过后大放光彩。
- Encoder(编码器):简单来讲,Encoder理解文章内容,传递给Decoder。
- Decoder(解码器):通过Encoder给的结果,生成对应的任务。
- BERT (Bidirectional Encoder Representations from Transformers): transformer的encoder部分,通常用作文章分类,命名实体识别等任务。
- GPT (Generative Pretrained Transformer):与BERT相反,只用了decoder部分,通常用作生成任务。