LoRA微调Twitter-roBERTa-base for Sentiment Analysis
这两天在准备一些简历和面试的东西,终于也是要迈出求职的这一步了。美国我是打算放弃了,主要感觉还是经历太少了,简历就看着没人家炫酷。也罢,回国吃烧烤也很香。
前两天面试了百度的NLP算法实习生,感觉是寄了,因为是个日常实习,也没办法中途回国。不过面试的时候提到了上学期做的一个小项目,就是用Hugging Face上的模型做情感分析,也谈到了微调。
0. 前戏:LoRA
LoRA, 全名Low-Rank Adaptation of Large Language Models,在2021的某个夏天,在一伙微(巨)软(硬)的研究员疯狂玩弄线性代数后,LoRA横空出世。
死去的线代知识准备发起攻击了!
Rank这个概念在我们小学二年级的时候就学过,指的是矩阵的秩,行向量或列向量中最大线性无关组的向量数量。可以理解为矩阵里真正包含信息的行数。
例如:
\begin{pmatrix} 1 & 0 & 1 \\ 0 & 1 & 1 \\ 0 & 2 & 2 \\ \end{pmatrix} 是一个秩为2的矩阵,因为第二行和第三行是一样的。
\begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{pmatrix} 是一个满秩(秩为3)的矩阵。
而低秩(Low-Rank)简单来说就是矩阵中存在大量线性相关的向量,从而导致矩阵的秩远小于满秩。
实际上,在深度学习的神经网络中,存在大量的的矩阵运算,而其中的矩阵随着参数量增加,极大可能矩阵就是低秩的,从而一个思想就应运而生了:在微调更新参数时,为什么要更新全部参数呢,只更新必要的参数不就好了吗?也就是说,对于一个低秩矩阵,只更新线性无关的向量不就完了吗。
奇异值分解
特征值分解针对方阵,可根据特征值将矩阵分解为三个较小矩阵相乘。对于非方阵(例如m = 20,n = 15),我们可以根据类似思想用奇异值分解,将矩阵分解为三个小矩阵。
奇异值分解是一种将任意矩阵分解为三个特定矩阵乘积的方法,形式为 \(W=UΣV^T\)。其中:
- \(W\) 是原始矩阵。
- \(U\) 是一个包含了左奇异向量的正交矩阵。
- \(Σ\) 是一个对角矩阵,对角线上的元素是奇异值,这些奇异值按从大到小的顺序排列。
- \(V^T\) 是一个包含了右奇异向量的正交矩阵的转置。
那么对于一个低秩矩阵,我们可以只保留前关键信息来进行降维。
举个例子,假设\(m = 20, n= 15, r = 5\),
import numpy as np # 生成一个低秩矩阵 W np.random.seed(0) m, n, r = 20, 15, 5 # m x n 矩阵,秩为 r U = np.random.randn(m, r) V = np.random.randn(n, r) W = U @ V.T # W 是 m x n 但实际秩为 r # 对矩阵 W 进行奇异值分解 U_svd, S_svd, VT_svd = np.linalg.svd(W, full_matrices=False) # 保留前 k 个奇异值 k = 5 U_k = U_svd[:, :k] S_k = np.diag(S_svd[:k]) V_k = VT_svd[:k, :] A = U_k @ S_k B = V_k # 构造近似矩阵 A_k W_k = A @ B np.random.seed(1) X = np.random.randn(n, 1) # n = 10 # 计算不同近似秩 r 下的 y y_original = W @ X y_r5 = W_k @ Xy_original == y_r5 # True W.shape[0] * W.shape[1] # 300 U_k.shape[0] * U_k.shape[1], S_k.shape[0] * S_k.shape[1], V_k.shape[0] * V_k.shape[1] # (100, 25, 75) A.shape[0] * A.shape[1],B.shape[0] * B.shape[1] # (100, 75)由此可以看出,原矩阵参数为300,低秩矩阵参数量为200,实际上,作者多做了一次矩阵运算,就是说\(A=UΣ\) 和 \(B=V^T\), 从而参数量为175。
注意!以上例子是在我们实际知道秩是多少,所有降维过后相当于保持了所有信息,实际情况是我们需要估算r。r越接近n, 涵盖的信息越全面。
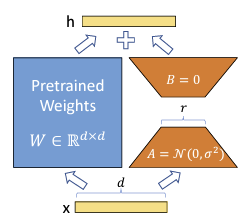
LoRA
在LoRA里,就是用了如上思想,将大矩阵拆分为小矩阵,同时冻结原矩阵。最后训练微调小矩阵在加回原矩阵,完成微调。
1. LoRA微调Twitter-roBERTa-base for Sentiment Analysis
以上都是铺垫,下面直接实操,上代码。预训练模型用Hugging Face上基于Bert用Twitter微调的情感分析模型。微调数据集在Kaggle上寻找对于AI态度的文章数据集 Public Perception of AI。我没有进行清理或者审查文章内容,只是用于演示目的。
导入、安装必要包
!pip install transformers datasets evaluate accelerate peft
import numpy as np
import pandas as pd
import torch
from transformers import RobertaModel, RobertaTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, DataCollatorWithPadding,AutoTokenizer
from peft import LoraConfig, get_peft_model
from datasets import Dataset, DatasetDict
from sklearn.model_selection import train_test_split读取数据
df = pd.read_csv('/kaggle/input/public-perception-of-ai/robot-ai-all-public.csv')
df = df[~df['Paragraph'].isna()]
df = df[~df['Article ID'].duplicated()].reset_index(drop = True)
df = df[['Paragraph', 'AI Mood']]
df.columns = ['text', 'label']
df.reset_index(drop=True, inplace=True)
mapping_dict = {1: 0, 2: 0, 3: 1, 4: 2, 5: 2}
# Apply mapping
df['label'] = df['label'].map(mapping_dict)预处理数据,和Twitter数据对齐
peft_model_name = 'roberta-base-peft'
base_model = 'cardiffnlp/twitter-roberta-base-sentiment-latest'
train_df, test_df = train_test_split(df, test_size=0.2) # 划分训练测试集
train_dataset = Dataset.from_pandas(train_df, preserve_index=False)
test_dataset = Dataset.from_pandas(test_df, preserve_index=False)
# 对齐数据
dataset = DatasetDict({
'train': train_dataset,
'test': test_dataset
})
tokenizer = RobertaTokenizer.from_pretrained(base_model,model_max_length=512)
def preprocess(examples):
tokenized = tokenizer(examples['text'], truncation=True, padding=True)
return tokenized
tokenized_dataset = dataset.map(preprocess, batched=True, remove_columns=["text"])
train_dataset=tokenized_dataset['train']
eval_dataset=tokenized_dataset['test'].shard(num_shards=2, index=0)
test_dataset=tokenized_dataset['test'].shard(num_shards=2, index=1)
# 情感标签
num_labels = 3
class_names = ['neg','mid','pos']
print(f"number of labels: {num_labels}")
print(f"the labels: {class_names}")
# id2label mapping
# 情感标签
id2label = {i: label for i, label in enumerate(class_names)}
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="pt")设置训练参数
为了演示,epoch,batch设置的较小
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy='steps',
learning_rate=5e-5,
num_train_epochs=1,
per_device_train_batch_size=16,
) 开始训练
def get_trainer(model):
return Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)
model = AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label)
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
peft_model = get_peft_model(model, peft_config)
print('PEFT Model')
peft_model.print_trainable_parameters()
## PEFT Model
## trainable params: 887,811 || all params: 125,535,750 || trainable%: 0.7072176650874352
peft_lora_finetuning_trainer = get_trainer(peft_model)
peft_lora_finetuning_trainer.train()
peft_lora_finetuning_trainer.evaluate()注意到上面代码,peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1) ,r为秩,lora_alpha可以理解为最后调整的参数对原矩阵的影响程度。一般经验告诉我们lora_alpha为r的两倍效果较好。
参数量从125,535,750 到887,811。
查看结果
from peft import AutoPeftModelForSequenceClassification
from transformers import AutoTokenizer
# LOAD the Saved PEFT model
inference_model = AutoPeftModelForSequenceClassification.from_pretrained(peft_model_name, id2label=id2label)
tokenizer = AutoTokenizer.from_pretrained(modified_base)
def classify(text):
inputs = tokenizer(text, truncation=True, padding=True, return_tensors="pt")
output = inference_model(**inputs)
prediction = output.logits.argmax(dim=-1).item()
print(f'\n Class: {prediction}, Label: {id2label[prediction]}, Text: {text}')
# return id2label[prediction]
classify( "AI is Cool") from torch.utils.data import DataLoader
import evaluate
from tqdm import tqdm
metric = evaluate.load('accuracy')
def evaluate_model(inference_model, dataset):
eval_dataloader = DataLoader(dataset.rename_column("label", "labels"), batch_size=8, collate_fn=data_collator)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
inference_model.to(device)
inference_model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = inference_model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(eval_metric) evaluate_model(AutoModelForSequenceClassification.from_pretrained(base_model, id2label=id2label), test_dataset)
#{'accuracy': 0.5786350148367952}
evaluate_model(inference_model, test_dataset)
#{'accuracy': 0.6350148367952523}由此可见,一个epoch过后正确率有所提升,效果肯定不如全参数微调,但快了许多。