Simple NLP — Sentiment Analysis
Translated by ChatGPT
A few days ago, during an interview, the interviewer suddenly asked me, “Why are you interested in pursuing a major related to data science?” I was momentarily at a loss for words. Saying it was purely out of love seemed somewhat insincere—it’s all about making a living, after all. There aren’t always grand narratives or beautiful visions.
However, I answered the interviewer like this: I said that perhaps, without us knowing, some simple data analyses could bring us a lot of information. This information could be business-related, societal, or even personal. I have the habit of keeping a daily diary (although most of it is just rambling…), and just a few days ago, I ran a simple sentiment analysis on my daily diaries using an open-source model from Hugging Face. I told the interviewer that, maybe, data analysis could also help me understand myself better.
So, I decided to start a “Simple” series, which is just about using libraries without needing deep technical knowledge.
0,My Diary
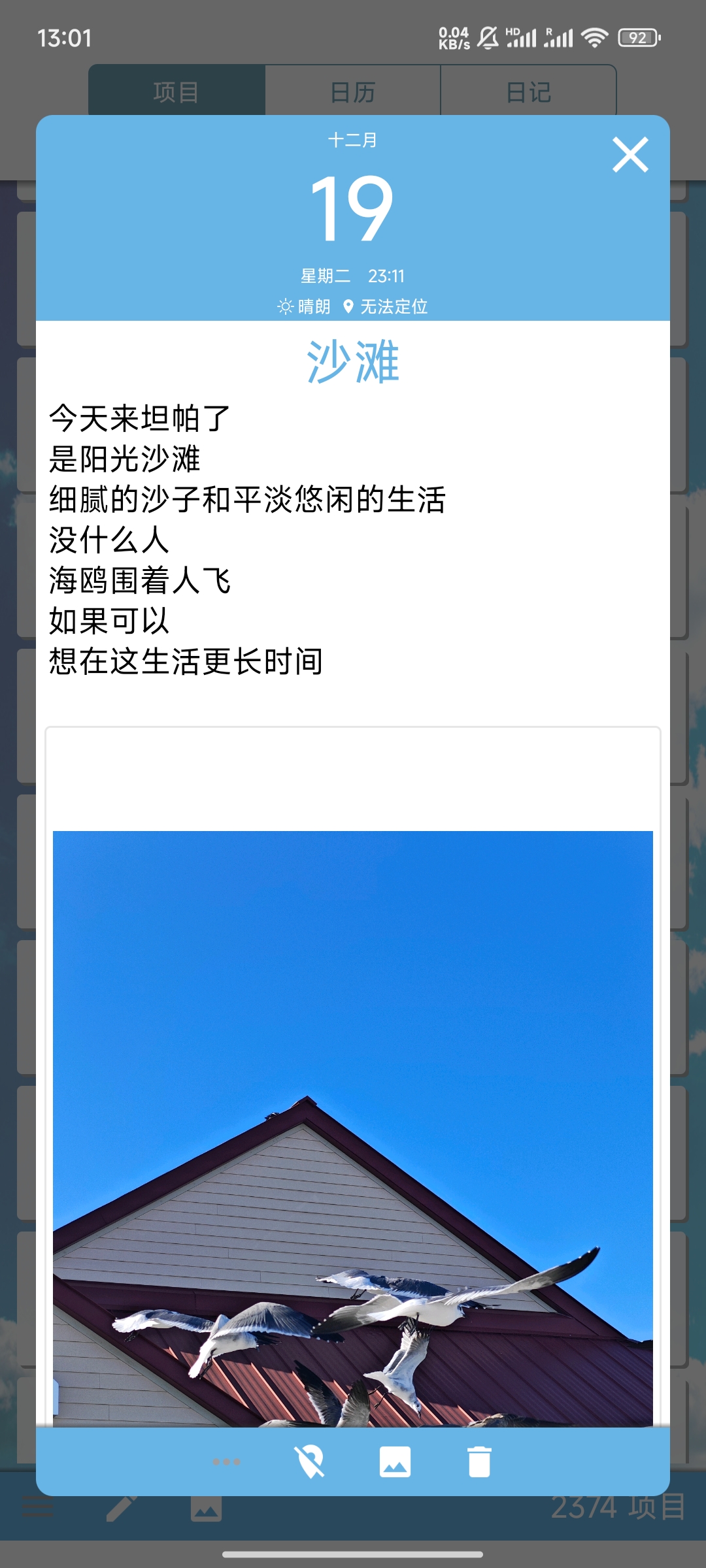
This is my habit of keeping a diary, writing some words, and then not using any punctuation marks (this is quite perverse), using line breaks to separate sentences. In Python, the data looks something like this: 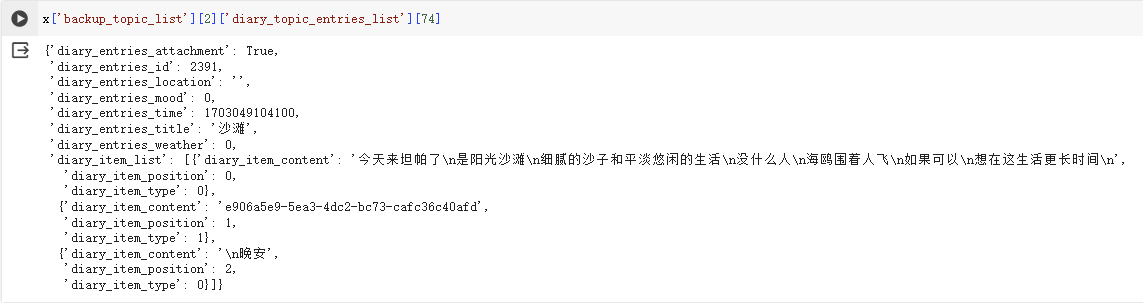
What I actually need is the content in diary_item_content. After a series of operations to extract the content, I do some simple preprocessing in preparation for analysis. (No code here, as everyone has their own diary writing habits.)

1, Direct Use of Online Models
1.1 Hugging Face
At Hugging Face, there are many deep models available for selection. These can be used for fine-tuning or directly out of the box. (Take it and use it!)
I selected xuyuan-trial-sentiment-bert-chinese, a sentiment analysis model fine-tuned on a Chinese dataset with BERT. Input text, and the output is roughly as follows:
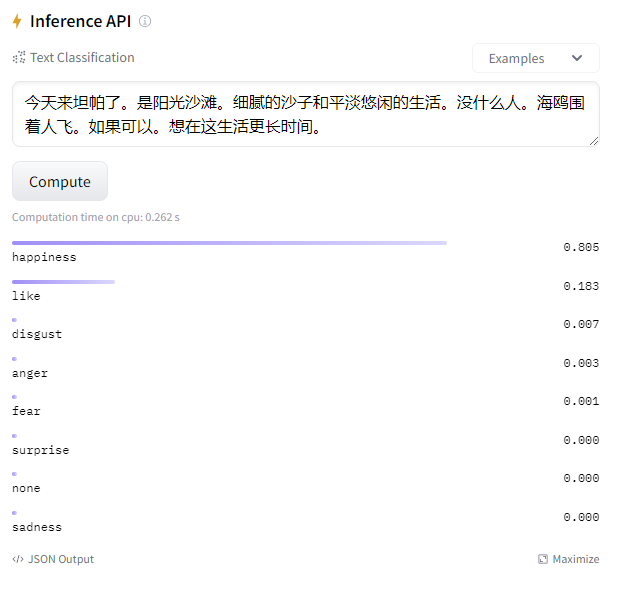
At first glance, it seems pretty accurate.
1.2 Python Usage
Using it in Python is straightforward, just:
from transformers import pipeline # Direct use of high-level API
pipe = pipeline("text-classification", model="touch20032003/xuyuan-trial-sentiment-bert-chinese") #Model is selectable使用例:
pipe('Today I came to Tampa. It is sunshine and beaches. Fine sand and a calm, leisurely life. Not many people around. Seagulls flying around people. If possible, I would like to live here longer.')
# output: [{'label': 'happiness', 'score': 0.8051121234893799}]
#or
pipe('Today I came to Tampa. It is sunshine and beaches. Fine sand and a calm, leisurely life. Not many people around. Seagulls flying around people. If possible, I would like to live here longer.', top_k=None) # top_k = None returns all categories
#[{'label': 'happiness', 'score': 0.8051121234893799},
# {'label': 'like', 'score': 0.18319253623485565},
# {'label': 'disgust', 'score': 0.006669812370091677},
# {'label': 'anger', 'score': 0.0025043778587132692},
# {'label': 'fear', 'score': 0.0013982513919472694},
# {'label': 'surprise', 'score': 0.0004570793535094708},
# {'label': 'none', 'score': 0.0004206936282571405},
# {'label': 'sadness', 'score': 0.0002451551263220608}]1.3 Simple “For Loop”
Not posting the code here, as it varies according to specific situations. Plus, it’s too crudely written to show off.
I stored the results in a dictionary, with the key being the diary entry number, and the value being the sentiments of different paragraphs.
print(res)
#{0: {0: 'like', 1: 'anger'},
# 1: {0: 'happiness', 1: 'like', 2: 'sadness', 3: 'disgust', 4: 'happiness'},
# 2: {0: 'sadness', 1: 'sadness'},
# 3: {0: 'disgust', 1: 'none', 2: 'sadness'},
# 4: {0: 'disgust', 1: 'happiness'},
# 5: {0: 'sadness'},
# 6: {1: 'disgust'},
# .....You could save it locally as a pickle:
import pickle
with open('DiarySentimentRes', 'wb') as f:
pickle.dump(res, f)2, My Sentiments
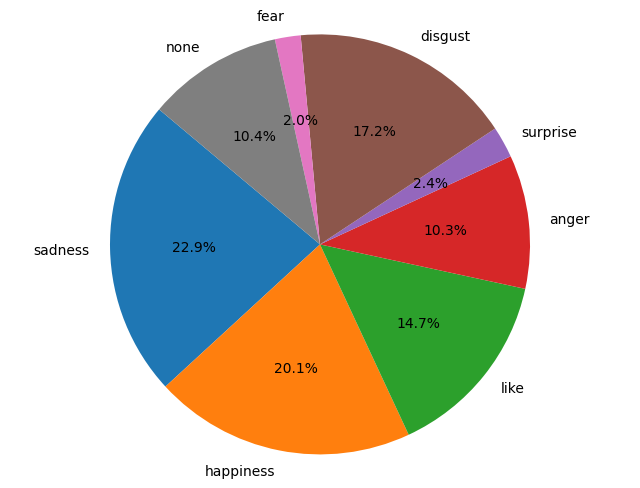
Next, I tallied the count of each emotion.
sentiCount = {'sadness':0, 'happiness':0, 'like':0, 'anger':0, 'surprise':0, 'disgust':0, 'fear':0, 'none':0}
for i,j in res.items():
for m,n in j.items():
if type(n) == list:
for k in n:
sentiCount[k]+=1
else:
sentiCount[n]+=1
print(sentiCount)
'''
{'sadness': 1227,
'happiness': 1075,
'like': 784,
'anger': 550,
'surprise': 129,
'disgust': 918,
'fear': 106,
'none': 558}
'''(It turns out happiness and sadness are almost equally distributed, probably because I only remember to write my diary late at night, hence the deep-night emo moments 😟)
I simply plotted a pie chart,
3, Some Basic Concepts
In today’s AI-booming era, operations have gradually become simplified, allowing for direct model usage without the need for extensive explanations. Most people can quickly get involved and learn about their interests in AI. AI drawing even has open-source graphical interfaces, eliminating the need for even basic programming languages like Python. Thus, everything seems simple (at least if you don’t delve too deep, perhaps).
Back to sentiment analysis, one could actually train a classifier themselves (SVM, Logistic Regression, etc.), and the results might not necessarily be worse than those of so-called deep learning models. Frankly, if there’s an appropriate dataset, hard training might yield even better results.
4, 一些小概念
Indeed, I prefer to discuss conceptual stuff later on, as starting with all sorts of technical jargon can be headache-inducing.
- Transformer: An encoder-decoder architecture that shone brightly after being mentioned in Attention is All You Need.
- Encoder: The Encoder understands the content of an article and passes the information to the Decoder.
- Decoder: Generates corresponding tasks using the results given by the Encoder.
- BERT (Bidirectional Encoder Representations from Transformers): The encoder part of a transformer, usually used for article classification, named entity recognition, and other tasks.
- GPT (Generative Pretrained Transformer): In contrast to BERT, it uses only the decoder part, typically for generative tasks.